问题
PAG 文件里的混合模式是从 AE 中导出的,然后使用 skia 内置的混合模式去实现,去掉 skia 之后,需要用原生的 OpenGL 来实现。
思路
既然 skia 内置的混合模式可以满足需求,那我们用 OpenGL 实现 skia 支持的就好,先看一下 skia 里面都有哪些混合模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
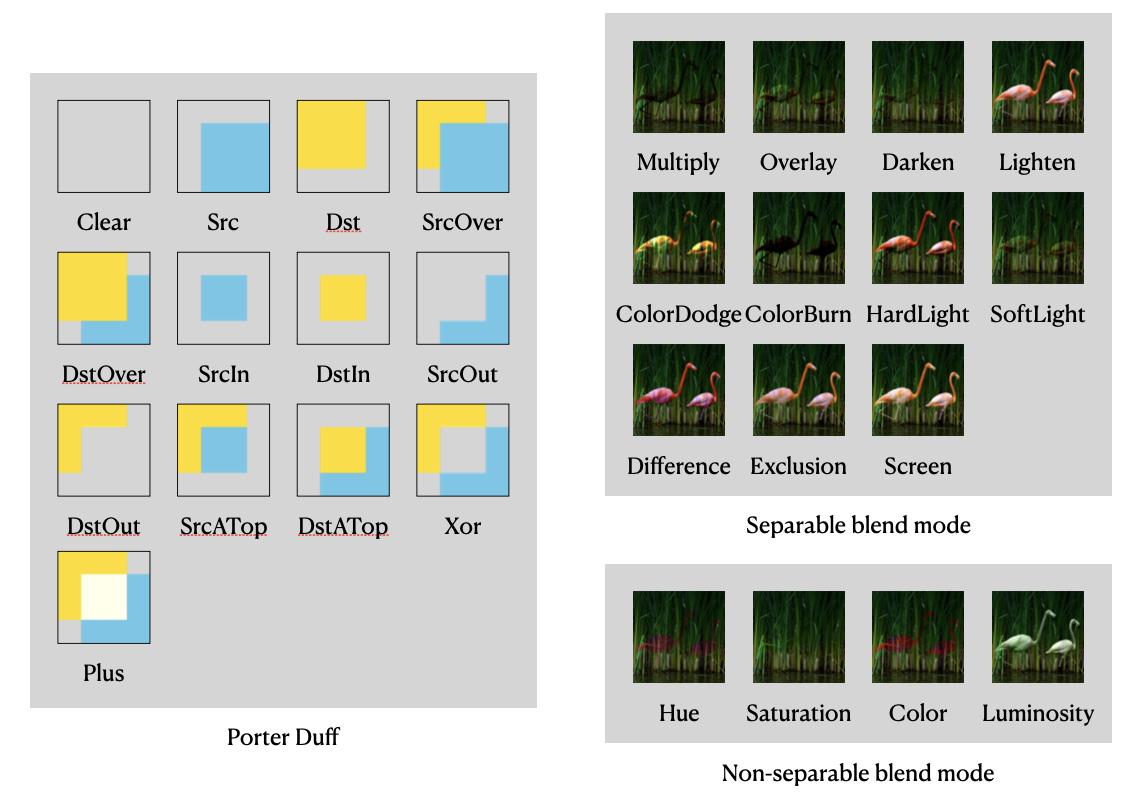
从实现方案上来说,这些混合模式都可以用 shader 来完成。其中kLastCoeffMode以上的混合模式也叫 PorterDuff 混合模式,它们还可以用 OpenGL 提供的 glBlendFunc来实现 。
解决
coeff blend mode
kLastCoeffMode以上的比较容易,在渲染之前把对应的参数设置好就行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
shader blend mode
用 shader 实现混合模式,我们需要在 shader 中访问当前 frame buffer 上的颜色分量,OpenGL 有一些 extension 提供了 frame buffer fetch 的功能,如下表所示。
| extension | color name |
| GL_EXT_shader_framebuffer_fetch | gl_LastFragData[0] |
| GL_NV_shader_framebuffer_fetch | gl_LastFragData[0] |
| GL_ARM_shader_framebuffer_fetch | gl_LastFragColorARM |
如果当前的 OpenGL 没有提供这些 extension,我们还有一个兜底措施,把这个 frame buffer 的内容复制到一个纹理(dstTexture)上,再把纹理传入 shader。

当然我们不需要把完整的 frame buffer 内容复制一份,因为我们的绘制区域可能只是局部。
复制局部 frame buffer 内容到纹理上,我们使用的是glCopyTexSubImage2D。这里还有一些其他的方式,比如glBlitFramebuffer,用这个的话,需要多创建一个 frame buffer,没有前一个方便和高效。
如果当前 frame buffer 已经绑定了一个纹理,而且当前的 OpenGL 也支持 glTextureBarrier,可以直接把这个绑定的纹理传入 shader,不过在绘制之前要调用一下glTextureBarrier。
shader 公式
skia 的 shader 公式来源是 w3c - Advanced compositing features 的文档。
注意:公式里的 RGB 是 Premultiplied 还是 Unpremultiplied。
D2D 也有一份 blend 公式。这两份基本是一样的,w3c 的更全一点。
总结
实现混合模式的整个过程,主要就是用 shader 实现的那部分比较复杂,因为需要考虑 OpenGL 的兼容性。
链接
skia
best method to copy texture to texture
OpenGL Reading from a texture unit currently bound to a framebuffer
SkBlendMode Overview
w3c - Advanced compositing features
D2D - blend